
NVIDIA has announced the latest TensorRT-LLM software that managed to push its top-of-the-line H100 cards achieving doubled output.
The optimization effort comes as a result of close workings with leading companies that heavily utilize AI as part of daily operations as Meta, Anyscale, Cohere, Deci, Grammarly, Mistral AI, and MosaicML all for one purpose of accelerating LLM inferencing through pure software magic.
The resulting package is the open-source TensorRT-LLM software usable by Ampere, Lovelace, and Hopper GPUs comprising of TensorRT deep learning compiler, pre and post-processing steps, optimized kernels, and multi-GPU/multi-node communication while shedding the needs for highly technical C++ / NVIDIA CUDA knowledge.

Citing official sources, the software update alone brought another fold of performance improvements, reaching up to twice the inferencing output in GPT-J 6B and about 1.77x for Meta’s Llama2.
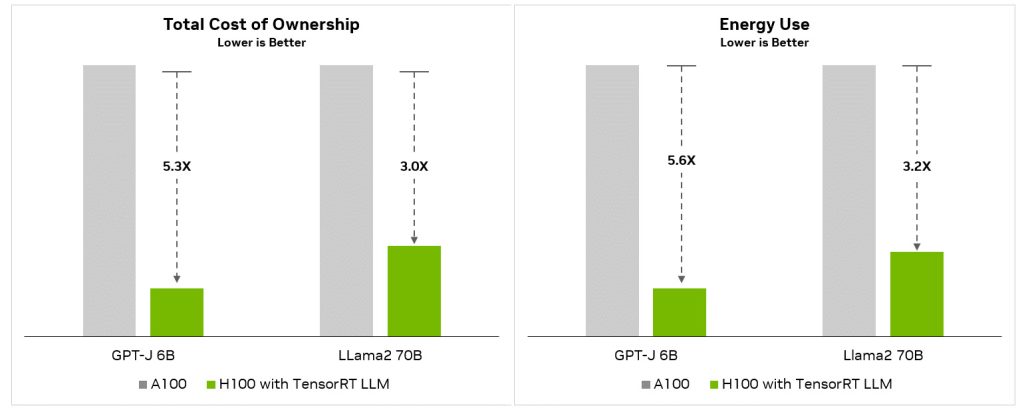
As performance output gets higher, especially on a multiplication scale, will also bring the Total Cost of Ownership (TCO) and energy consumption rating to a lower and better scale, resulting in better financial management and flexibility for data center owners – scale down for lower cost or scale up for more hardware at the same baseline cost.
When delving into the technical details of TensorRT-LLM, NVIDIA credits Tensor Parallelism which splits individual weight matrices across devices for efficient inferencing at scale + In-flight Batching that does almost the same thing to requests but instead of processing by per batch, they are immediately passed to the next phase instead of waiting.
The ability to convert model weights into the new FP8 format made possible through the Hopper Transformer Engine enabling a fast quantization process with reduced memory consumption is also one of the big keys to why such performance is possible on the H100.
Availability
Early access for the NVIDIA TensorRT-LLM is now available and will soon be integrated into the NeMo framework for NVIDIA AI Enterprise. Additionally, a lot of the ready-to-run versions are already optimized including Meta Llama 2, OpenAI GPT-2 and GPT-3, Falcon, Mosaic MPT, BLOOM, and a dozen others – all with an easy-to-use Python API.








