
MLPerf 3.0 has been released last week yet NVIDIA has achieved yet another level of inferencing capabilities with its flagship H100 and L4 GPUs.
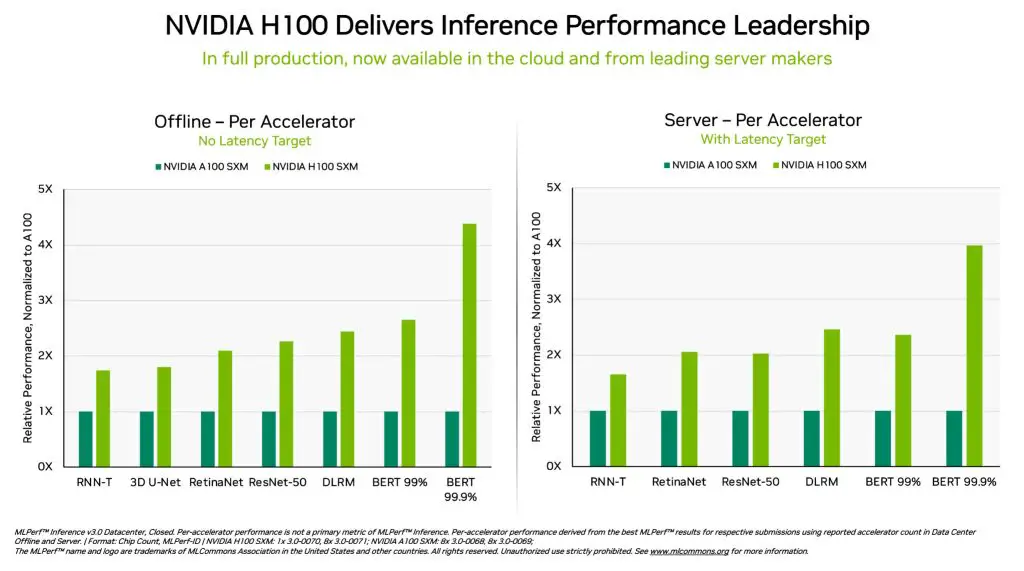
The leaps in performance are higher than one could expect when comparing the last-gen A100 with the current H100 DGX systems that result in 4 times higher figures and of course, currently the best in MLPerf Inference 3.0 driven data center workloads. When looking at H100’s current results and the ones made during its debut about 6 months ago, the improvement is at about 54%.
The Hopper architecture plus Transformer Engine are attributed by NVIDIA as the core backbone of why Generative AI is powerful and capable in 2023 which has already and will continue to bring disruption to all sectors of businesses across the world.
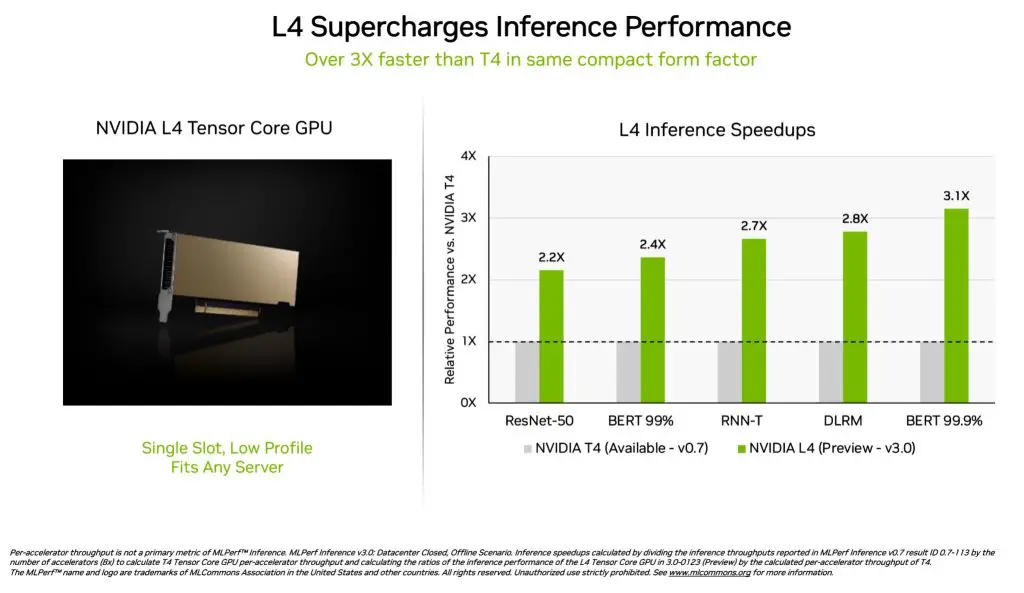
On the other hand, the L4 GPU focuses on accelerating workloads for video, virtualization, graphics, AI, and more, delivering a strong impression with an astounding 3x faster speed compared to the older T4 counterpart. One of the most performance-hungry models, the BERT model, shows the biggest leap in performance improvement thanks to FP8 support.
Aside from these two groundbreaking results, NVIDIA also entered the networking space by running similar tests in a remote setting, and to everyone’s surprise, it can deliver up to 96% of local performance with a 4% loss coming from the transmission latency of data across connected systems while ResNet-50 test can achieve the same rate as locally-processed simulation.
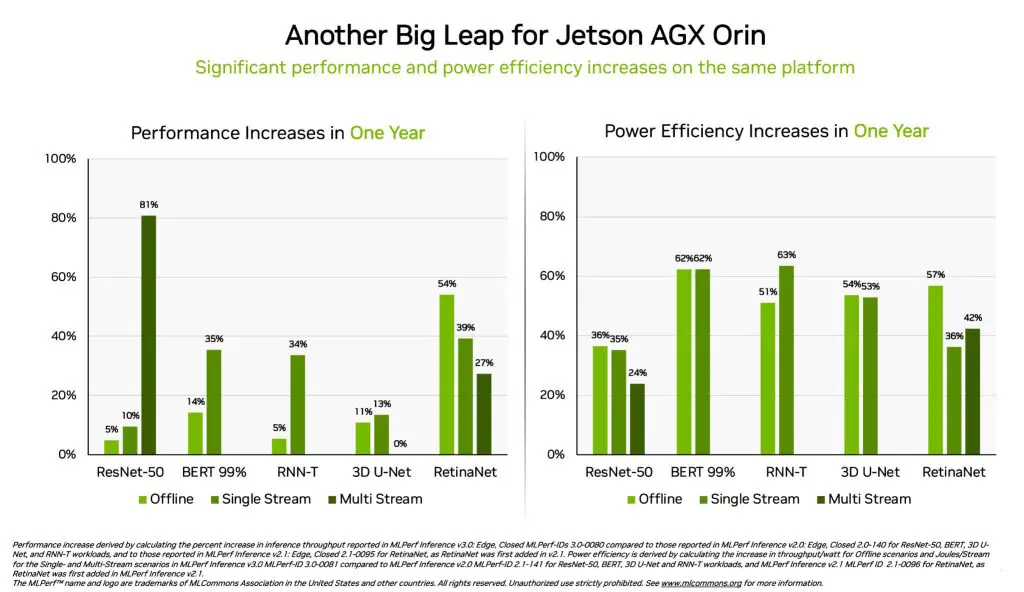
A fair mention for the System-on-Module family Jetson AGX Orin where performance and power efficiency improvements across the board with up to 81% increase in computing power. The efficiency rate is also one of the important points where deployments running on portable power sources can now sustain the system for a longer period of operation time.
More can be read in this blog post.









