

Alibaba just dropped the new Qwen3-Next, a fresh model architecture that’s designed for long-context understanding, massive parameter scaling, and seriously efficient computation. The company says this leap forward comes from a mix of architectural tricks like a hybrid attention mechanism and a super-sparse Mixture of Experts setup, which together give it strong performance while keeping costs low.
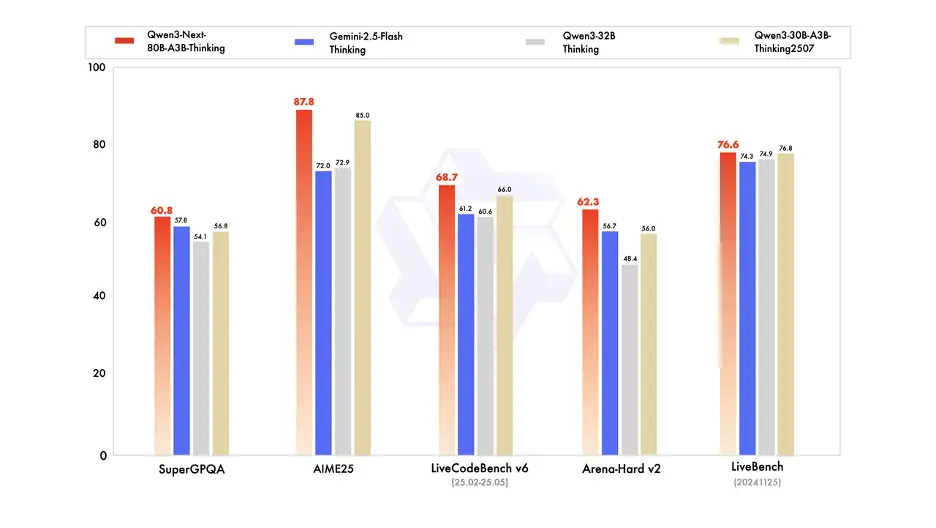
The first model using this design, Qwen3-Next-80B-A3B-Base, packs 80 billion parameters but only lights up 3 billion of them during inference. Both Instruct and Thinking versions are now open-sourced and up on Hugging Face, Kaggle, and Alibaba Cloud’s ModelScope. What makes it stand out is how it beats the dense Qwen3-32B while using less than 10% of its training cost and delivering over 10x higher throughput for tasks with context lengths beyond 32K tokens.
Alibaba also built specialized versions such as the Qwen3-Next-80B-A3B-Instruct model hits the same performance level as the company’s 235B-parameter flagship, but with native support for a 256K context window that can stretch up to a million tokens. Meanwhile, the Qwen3-Next-80B-A3B-Thinking model shines at complex reasoning, even outperforming one of the top closed-source reasoning models and getting close to Alibaba’s own 235B-parameter thinking variant.
The secret sauce here includes hybrid attention (blending Gated DeltaNet and Gated Attention to improve in-context learning while cutting down computation), an ultra-sparse MoE setup that only activates 3.7% of parameters per inference, and multi-token prediction for faster, smoother performance. On top of that, the model was trained on 15 trillion tokens pulled from the larger Qwen3 corpus, making it more deployment-friendly—even for consumer-grade hardware.
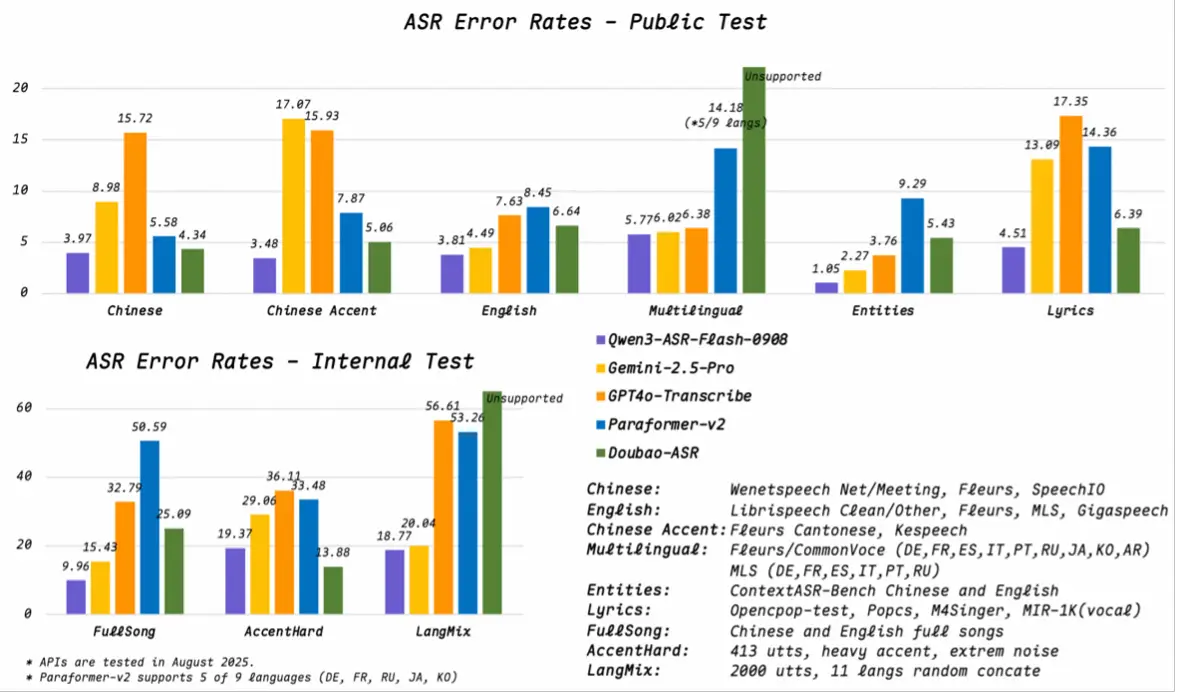
But that’s not all Alibaba has been cooking up. Just days ago, it launched Qwen3-ASR-Flash, a new automatic speech recognition model trained on tens of millions of hours of multilingual audio. It works across 11 major languages and multiple Chinese dialects, while also handling a wide range of English accents. It is even capable of transcribing song lyrics even with heavy background music, while filtering out noise in tough acoustic environments. Developers can play with it via APIs on Alibaba Cloud’s Model Studio, Hugging Face, or ModelScope.
And last week, Alibaba gave an early look at Qwen3-Max, its largest non-thinking model so far, weighing in at over 1 trillion parameters. Already ranked No.6 in Text Arena, Qwen3-Max-Preview handles both Chinese and English instructions more reliably than older models, with fewer hallucinations and stronger performance in math, coding, logic, and reasoning. Supporting 100+ languages and optimized for workflows like RAG and tool calling, it’s positioned as a versatile powerhouse for advanced AI tasks.
With Qwen3-Next, Qwen3-ASR-Flash, and Qwen3-Max lining up, it’s clear Alibaba is doubling down on efficiency, multilingual strength, and scaling AI to new heights.








